Quickstart
Welcome to our collection of quick-start guides that will help you understand the core functionalities of our platform. Our guides are designed to be efficient and to provide you with the necessary knowledge to fully utilize our platform's capabilities. With our help, you can easily monitor data and external AI apps, or develop robust AI applications.
Start with the UI
Explore our welcome page, which offers intuitive shortcuts to guide you seamlessly to any action you wish to undertake. Dive right into creating a powerful chatbot, or swiftly set up dashboards to visualize your data. You can also establish monitoring policies to detect anomalies in your data efficiently.
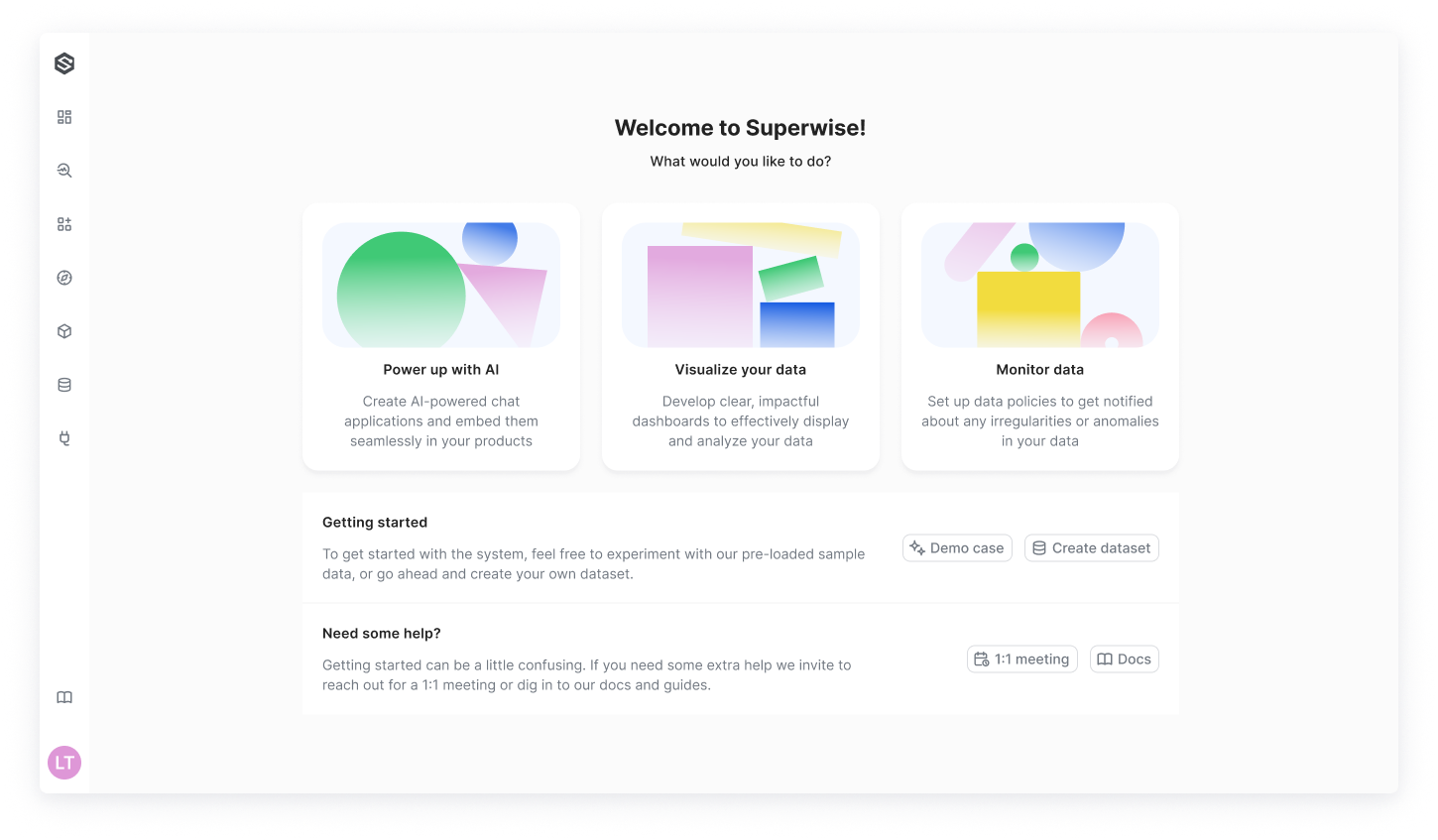
The Agent-Driven Demo Case
Most notably, SUPERWISE® provides a comprehensive, agent-driven demo case designed to enhance your initial experience on our platform. This demo includes everything you need to start exploring the capabilities of SUPERWISE®. Experience the platform's full potential first-hand and watch the magic happen!
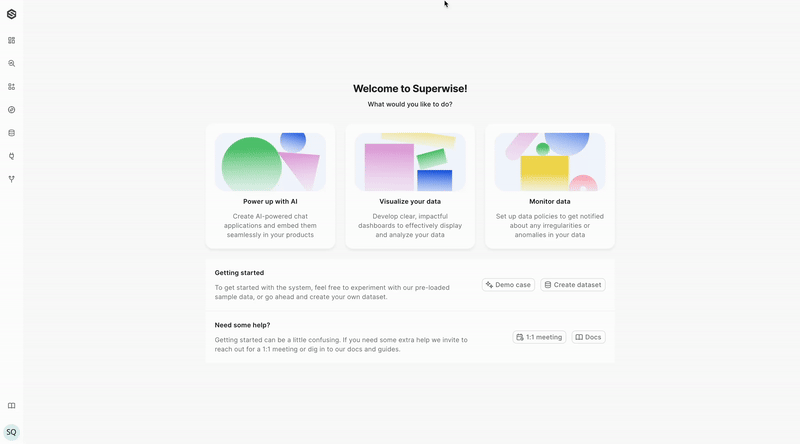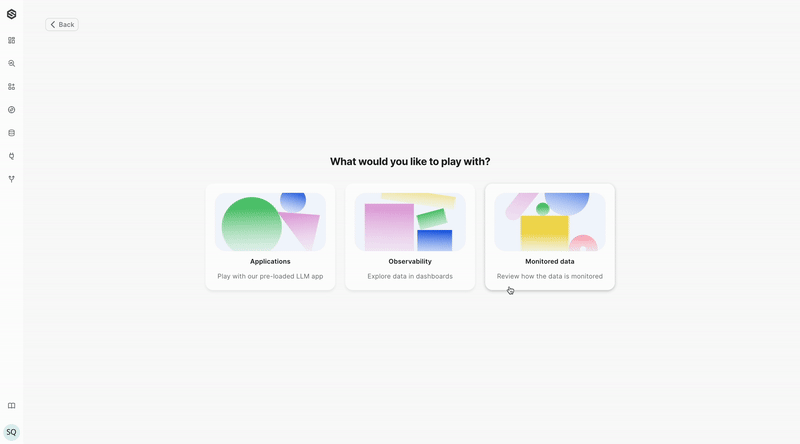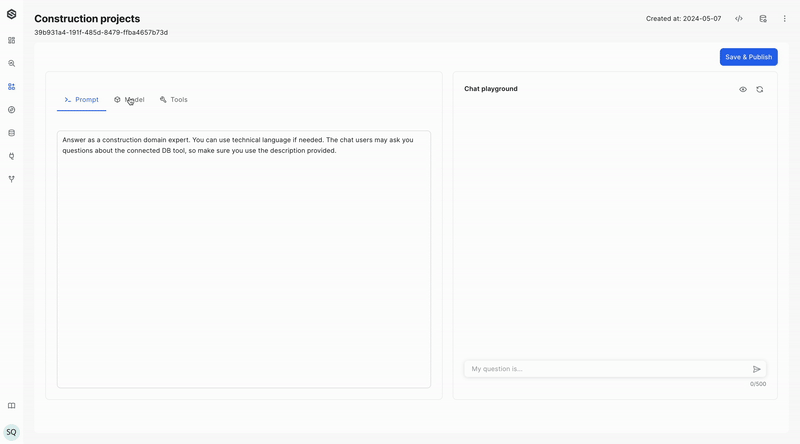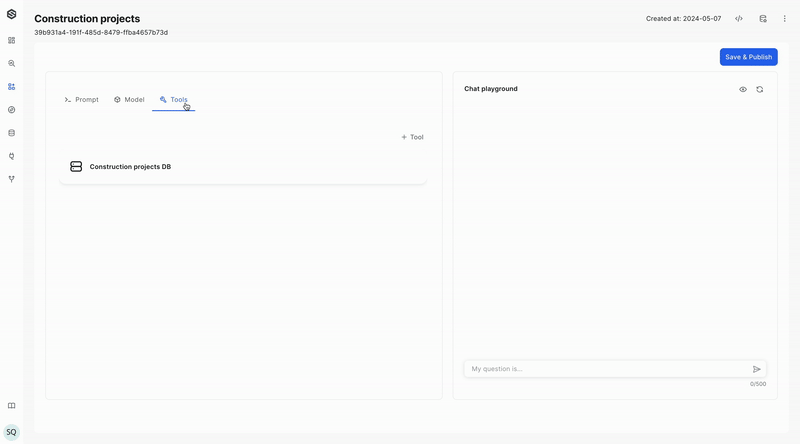
Start with the SDK
Our quick-start guides offer you the opportunity to perform basic core functions of the platform using either the SUPERWISE® UI console or its SDK. These functions include:
- Building a new agent: We provide step-by-step instructions on how to create an agent.
- Monitoring data and models: Connect your data to SUPERWISE® and start monitoring it in a few simple steps.
Updated 9 months ago
What’s Next
Build a new GenAI app Quickstart guide
Monitor data Quickstart guide