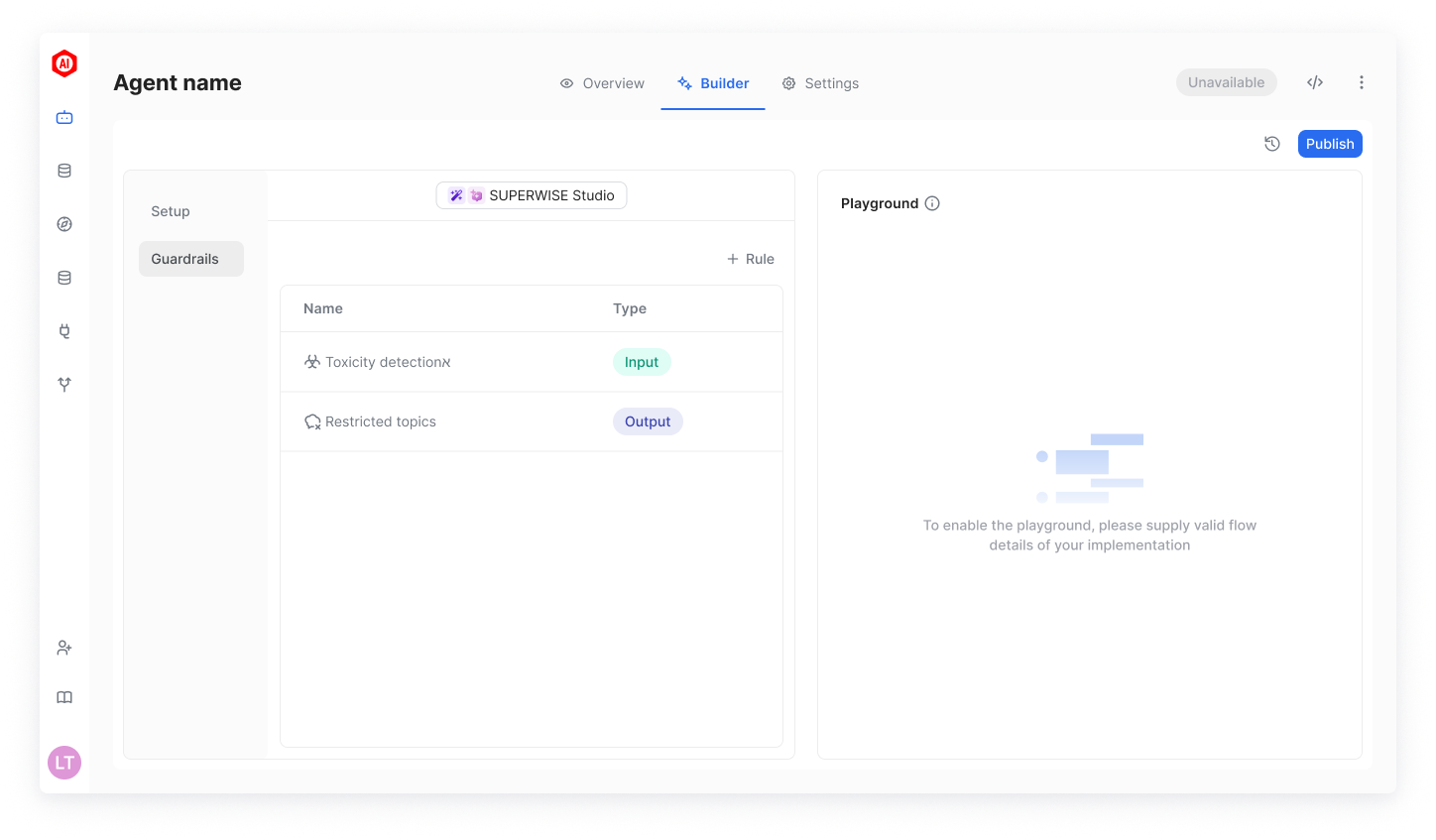
Configure a Guardrail
A guardrail is defined by a set of rules and checks that will be performed on an agent's input or output (or both) interactions. To define such rules, simply add a new rule to your guardrail using one of the available types of rules.
You can configure the same type of rule more than once.
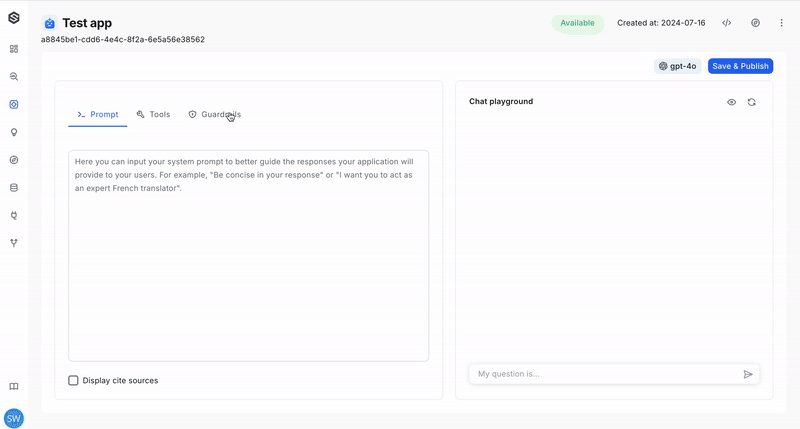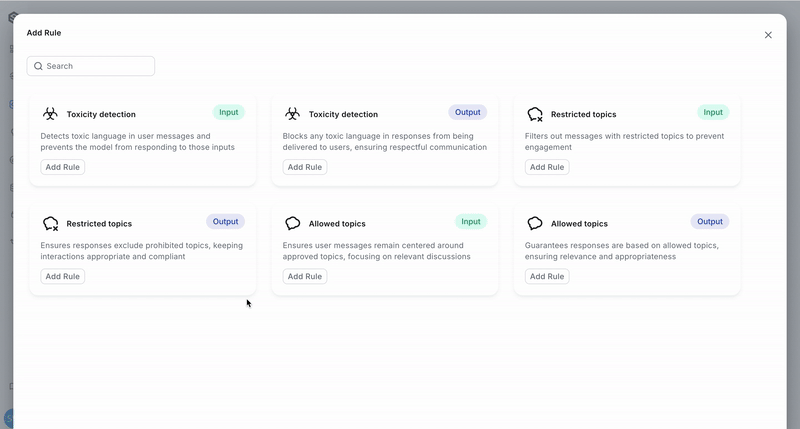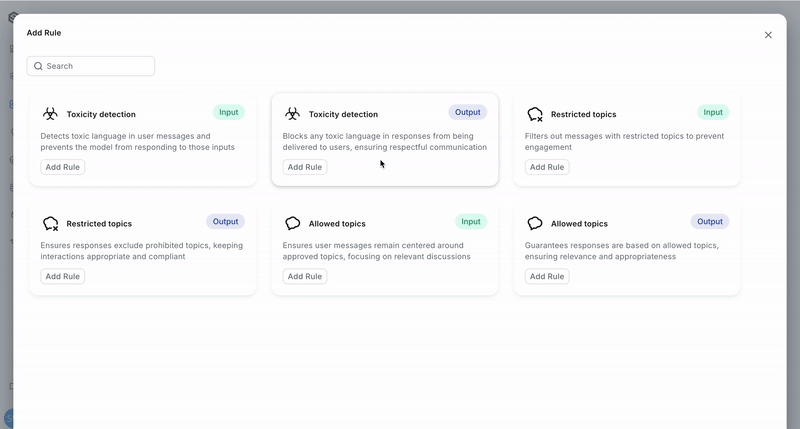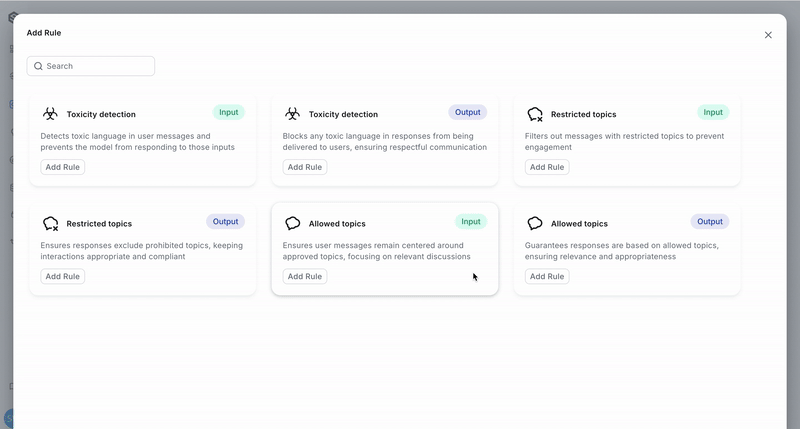
Adding a Rule
When configuring a rule, you will need to supply the specific settings of the rule and declare whether it should be applied to agent inputs, outputs, or both. The types of rules that can be configured are:
- Toxicity detection
- Restricted topics
- Allowed topics
- Correct language
- Competitor check
- String check
- Jailbreak detection
- PII detection
- Resolution level
- Sharpness level
- Semantic image
- Image tampering detection
- License plate
- Face detection
face-detectiondoc:## Test the Guardrail
While configuring the rule, consider using the testing box, which allows you to quickly test your specific current settings and see how they will be applied. This way, you can quickly adjust your settings (e.g., change the sensitivity level of your rule) and see how it will impact the check result. Anytime a check of a specific rule is conducted, it can result in either a "Passed" or "Violated" outcome. Configuring more than one rule for a given guardrail means that all the configured rules will be executed together on a given interaction (according to the input and output settings of each rule). If one or more of the rule checks result in a "Violated" outcome, the entire guardrail result will be considered "Violated." If all configured rules are passed, the guardrail result will be considered "Passed."
Once all rules are in place, users can use the guardrail playground section where the guardrail will be executed on different input or output examples. Each test will summarize which guardrails passed and which were violated. [image of playground]
Via the SDK
Here is an example of adding multiple rules for a given guardrail.
print("SUPERWISE currently offers the following Guardrules:")
for index, type in enumerate(sw.guardrails.gardrules_types()):
print(f"{index + 1}. {' '.join(type.capitalize().split('_'))}.")Two toxicity rules are defined below, set with different thresholds to test the rule sensitivity.
from superwise_api.models.guardrails.guardrails import ToxicityGuard
low_toxicity_guard = ToxicityGuard(name="Low toxicity guard", tags=["input"], threshold=0.1, validation_method="sentence")
high_toxicity_guard = ToxicityGuard(name="High toxicity guard", tags=["input"], threshold=0.8, validation_method="sentence")To test your configuration, use the "run_guardrules" function:
results = sw.guardrails.run_guardrules(tag="input", guardrules=[low_toxicity_guard, high_toxicity_guard], query="Heck ye")
for result in results:
if not result.valid:
print(f"Guardrail '{result.name}' was violated.")
print(f"Violated message: {result.message}")Updated about 1 month ago